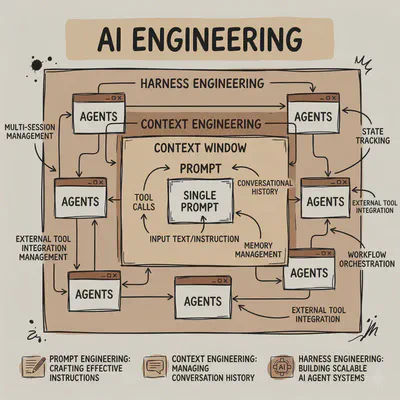
Prompt, Context, Harness: The Three Phases of AI Engineering

Over the past few years, AI engineering has gone through three distinct shifts: prompt engineering, context engineering, and now Harness Engineering. On the surface it looks like swapping in new buzzwords — and to a certain extent, it is. But each term marks a turning point in how we understood what was actually failing. The questions we asked got sharper with each phase, because our understanding of how these systems work got sharper too. There’s also a quieter pattern running underneath: each phase emerged not to expand what AI could do, but because something specific kept failing. Every new layer is compensatory — built from necessity, to cover a gap the model couldn’t close on its own.
When Phrasing Was the Problem
When large models first took off, everyone noticed the same thing: the same model could produce wildly different results depending on how you phrased your request. Ask it to “help me create a project charter” and you’d get something generic, impressive but useless. Reframe the request, and the output would change immediately. The conclusion people drew: the model can do it — you just haven’t explained the problem clearly. So everyone started obsessing over prompts: role setting, style constraints, few-shot examples, output formatting, and so on. Why do these work? Because a large model is essentially a probability generation system that’s guided by your input. Give it a persona, and it answers in that persona. Give it examples, and it follows the pattern. Emphasize a constraint, and it treats that as the focal point. The essence of prompt engineering isn’t about commanding the model — it’s about how to communicate effectively to total strangers.
But prompt engineering hit a ceiling quickly. Many tasks don’t just require clear communication — they require the model to actually know things. And often it doesn’t. The two failure modes this creates are familiar to anyone who’s used AI professionally: hallucination and generic answers. The model either fabricates facts with confidence or retreats into vague, unhelpful output. Prompts can’t fix either problem, because prompts can only activate what’s already there. They excel at establishing task constraints, guiding output style, and drawing out latent capabilities. They’re not good at supplying missing knowledge, managing dynamic information, or tracking state across a long chain. Prompts solve communication problems. Not information problems.
Prompts were sufficient in the chatbot era — short tasks, short chains, minimal background information. Every time you talk to AI, it is like talking to a government agent through a tiny kiosk window. They don’t know you, and you don’t know them. This would only work well when the answer is the same regardless of who’s asking: think definition-based exam questions, or a simple factual lookup. Plenty of real use cases fit that mold. But many of our actual problems are situational. The right answer depends on who’s asking, what they’ve already tried, what constraints they’re working under, and what information they have access to. For those questions, speaking clearly isn’t enough. The model needs context.
The Supply Chain, or Context Engineering
That’s when the second stage began. The model wasn’t just answering questions anymore; it needed to operate in real environments. Talking with multiple parties, calling browsers, writing code, querying databases, using tools, passing results across steps, adjusting plans based on external feedback. The problem changed. It was no longer whether a single answer was right or wrong. It was whether the entire task chain could run to completion.
Take a realistic task: instead of “create a project charter,” you ask the model to analyze a requirements document, identify risks, cross-reference historical projects, milestones proposed by the project sponsor in email exchanges. A single prompt can’t carry all that. The model needs the current requirements document, past review records, relevant specs, current goals, intermediate conclusions from earlier steps, the target audience, and tone guidelines. Context engineering reduces to one principle: what the model doesn’t know, the system must feed it — at the right time.
Context here isn’t just a few paragraphs of background information. In engineering terms, it’s the sum of everything that affects the model’s current decision: user profile, conversation history, retrieval results, tool outputs, current task state, intermediate work products, system rules, safety constraints, and structured outputs from other Agents. Think about context as your supply chain: where does your raw material come from, when does it arrive, at what cost?
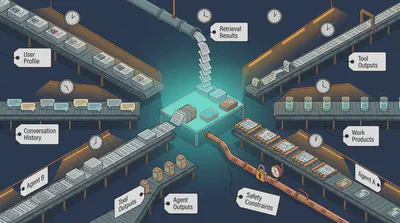
Start with a basic constraint: the context window is fixed. Every model is trained with a specific window size, and that window can’t be expanded after the fact — enlarging it would require retraining from scratch at significant cost. Think of it as a table. Everything the AI can “see” during a conversation has to be placed on that table. When the table fills up, something has to go. What gets dropped might be exactly what the model needed.
Solving this isn’t straightforward. It requires knowing how to compress long texts intelligently, when to keep conversation history verbatim and when to summarize it, and whether to pass tool outputs in full or filtered. For longer-running systems, you need a memory layer that persists across sessions — one that extracts what matters from each conversation and consolidates it over time: your projects, your preferences, your working context. We’re building early versions of this now, but compared to how human memory actually works, what we have today is still quite primitive.
RAG is another piece of the puzzle — and a revealing one, because it’s both a genuine solution and a demonstration of the problem’s depth. The value proposition is simple: when knowledge isn’t baked into the model’s parameters, retrieve it at runtime and inject it into context. In practice, this opens a chain of serious engineering decisions: chunking strategies, ranking algorithms, embedding choices, whether and how to capture relationships between semantic objects. Even with careful engineering, results can fall short — because the underlying retrieval mechanism has fundamental limits.
Context engineering is also about what not to load. Too much information scatters attention. If you want to extend the model’s capabilities, you have to load those capabilities into the context — but that consumes space you may not be able to spare. The recently popular concept of Skills is a direct response to this tension. If you dump a dozen tool descriptions and parameter definitions into the model upfront, it theoretically knows more; in practice it often performs worse. Skills solves this through progressive loading: the model starts with a minimal index of what it can do, then loads detailed instructions and scripts only when a specific capability is actually triggered. Capabilities on demand, not capabilities in bulk.
When One Agent Isn’t Enough: Harness Engineering
By 2026, agentic AI had moved from marketing pitch to working reality. Agents were no longer a concept in academic papers or a promise in product announcements — they were showing up in actual engineering pipelines. And they brought their own class of problems.
The challenge wasn’t any single agent failing at its task. It was how a team of agents holds together. Even with correct information and well-crafted prompts, a model might form a sound plan and then drift during execution — misreading a tool’s return value, slowly deviating over a long chain while the system sits unaware. Context engineering, at its ceiling, is still about what a single agent can know and see — how one individual does their work. But many tasks aren’t harder versions of what one agent can handle. They’re structurally different. There are simply things you cannot ask one individual to do. A brilliant surgeon with perfect information still can’t also be the anesthesiologist. Once a model starts taking continuous actions across a team, a different question surfaces: what supervises it, constrains it, and catches it when it strays?
Think of it as a Full Self Driving vehicle going from point A to point B. It all sounds good on paper: the route is planned, distance optimized, driving time estimated. But the car doesn’t drive in a virtual world made for the test. It goes into the real world where anything could happen: traffic accidents, road closure, careless driver or pedastrian, or evil sabotager. If any of these happen on the route, how do we re-evaluate the situation and decide upon a strategy (to wait, to change route, to abort)?
That brings us to the third stage. Harness — the word means reins, or a restraining apparatus. If the first two generations of engineering focused on making the model think better, Harness focuses on keeping the project on track. It’s the governance layer for the entire team.
Here’s an analogy. Say you’re sending a new employee to handle an important client meeting. Prompt engineering is briefing them on the script: greet the client, introduce the plan, ask about needs, confirm next steps. The focus is on what to say. Context engineering is making sure they walk in prepared: the client’s background, past communication records, pricing sheets, competitor info, the goals for this meeting. The focus is on having the right information. But if the meeting is truly high-stakes, you go further — give them a checklist, ask them to check in at key moments, require meeting notes afterward, review for any deviations and correct them immediately, and evaluate the outcome against clear criteria. That’s Harness. The focus shifts from “did they say the right things and have the right information” to “is there a mechanism for continuous observation, correction, and final acceptance.”
These three phases aren’t mutually exclusive — they’re nested. A useful way to see this: imagine you need to drive to Costco. Prompt engineering is turn-by-turn instructions: go straight, turn left, merge onto 280 south. Context engineering is telling the driver the destination and letting them plan the route — keeping the goal in view across the whole trip. If you stop for gas and restart, the destination should persist. If there’s an accident on 280, the system should reroute. That’s what a navigation app does.
Harness engineering is what happens when you need to chain the driving task into a series of related tasks. Shopping at Costco is its own complicated, creative process — a long chain of decisions that no one could have fully scripted in advance. You spot a fancy patio chair on display and realize you need your wife’s opinion. You take a picture and send it to her. She calls back on FaceTime. While you wait, you do a quick web search to compare prices on Amazon and Home Depot. You load the groceries into the car, drive home, and then figure out what goes in the freezer, what goes in the fridge, and what goes in the pantry. You rope someone in to help unload, which requires coordination. You might have an errand to run on the way back — in which case you’re now thinking about the ice cream in the trunk and how long it has before it melts.
A Costco run. And it already contains every essential characteristic of Harness: planning, executing, delegating, checking, revising, consulting, coordinating, orchestrating.
What’s in the Harness?
Harness Engineering shapes how the team of agents works — by making explicit rules. The quality of these rules is what makes the difference between an AI “toy” and a production-grade “worker”. That governance layer has five components, ordered from the most established — already shipping in mature tooling — to the most experimental, still more research paper than product.

Context Management. Managing context for a single user in a single session is a tractable problem — the human handles most of it naturally, with a little help from the system. Managing context for a team of concurrent agents requires deliberate design. Because none of the agents can see each other’s work unless the harness puts it in front of them. None of them know their own scope unless the harness defines it. And none of what they produce gets folded back into the shared state unless the harness does the folding.
Think of it as jurisdiction. Every agent needs to know three things: what it’s responsible for (role and goal definition — who it is, what it’s supposed to do, what counts as done); what it inherits from above (context inheritance — which part of the main goal is relevant, what prior work it can assume, what constraints apply); and what it sends back (context return — once finished, what gets surfaced to the orchestrator and what gets discarded). Get any one of these wrong and the system develops blind spots. An agent that doesn’t know its scope will either over-reach or under-deliver. An agent that doesn’t know what to report will either flood the orchestrator with noise or swallow something it needed to keep.
The failure mode, when it emerges, is vivid. Anthropic documented a phenomenon they called context anxiety: as runtime extends and the context window fills up, the model starts losing details, dropping key points, and — in a striking behavior — seems to sense the approaching limit and begins rushing to wrap things up prematurely. The standard remedy is context compression: summarize the history and keep going. Anthropic found this insufficient. Compression makes the context shorter, but doesn’t eliminate the underlying burden — the model is still operating in the same cramped space, now with a lossy summary instead of the original. Their solution was more radical: hand the work off to a fresh agent with a clean context window, restore only the necessary state, and continue from there. It’s the engineering equivalent of hitting a memory leak and deciding to restart the process rather than keep patching. Context Management is what makes those handoffs seamless — and its absence is what turns them into restarts.
The Tool System. Without tools, a model is still just a text predictor — it can explain and summarize, but can’t touch the real world. Connect it to tools and it can browse pages, read files, write code, call APIs. The gap between a model that can only describe actions and one that can actually take them is the gap between a consultant and an employee.
A harness doesn’t just wire up tools. It solves three distinct problems in sequence. The first is selection: which tools to give. Too few limits what the agent can do; too many introduces confusion — the model starts misusing tools outside their intended scope, or hedges by calling several when one would do. The second is timing: when to call them. A well-designed harness enforces a basic discipline: don’t search when guessing is fine; don’t guess when the answer is one API call away. The third is digestion: how to feed results back. A tool that returns a hundred rows of data doesn’t help the model if all hundred rows go into context — it swamps the signal. The harness filters, condenses, and formats before passing results upstream.
These three problems compound — and compound silently. An agent tasked with researching a competitor’s pricing, given no tool discipline, calls the search tool eight times, each time dumping full results into context. By the fifth call, the context window is half-full with raw, contradictory data. The model struggles to reconcile the sources, hedges its conclusions, and produces something vague. With proper tool management: one targeted search, the harness extracts the three most relevant passages and passes only those upstream. Same question, same underlying data, dramatically different output. The best tool systems don’t make the agent smarter — they give it less noise to think through.
Orchestration. The key insight about orchestration is this: humans internalize team structure through experience. They know when to escalate, when to parallelize, when to just handle something themselves. Agents don’t have that. They rely on the harness to supply what humans build up over years of working together.
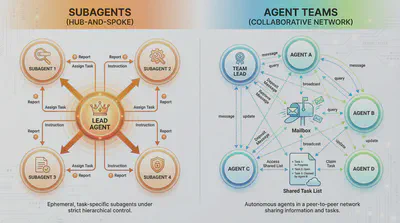
Two coordination models have emerged. The hub-and-spoke model routes everything through a central orchestrator — a master agent that decomposes the task, hands out assignments, collects results, and determines what runs next. Control stays at the center, like a traditional project manager. The team model (see deep-dive in the next section) is messier but more flexible — agents communicate with each other directly rather than waiting for instructions from above. Closer to how high-functioning agile teams actually work, where a designer and an engineer resolve a conflict without looping in the manager every time.
A working example of three-agent setup: if a complex and challenging task arrives, it first goes through a lead model (Claude) that handles architecture, reasoning, and synthesis, while delegating implementation to a diligent code-generation agent (OpenAI Codex) and web research to a retrieval-specialized agent (Gemini). Tasks branch out in parallel; results converge back at the center. That’s hub-and-spoke. Or a writing team where three models draft independently, then critique each other’s work before converging — that’s a team model. Neither is universally better. The harness decides which structure to use, enforces it, and ensures handoffs don’t lose state.
Memory and State Management. Every LLM is stateless by default. When a new request comes in to the server, the model doesn’t know what it’s already done, which conclusions it’s reached, or what’s been tried and failed. Whatever it needs to know must be explicitly supplied.
Think of building a house while hiring different workers every day. The framing crew doesn’t know what the foundation crew discovered. The electricians don’t know what the plumbers already ran through the walls. Without a system to track and deliver that information, work gets duplicated, conflicts get built in, and the foreman spends every morning reconstructing the project from scratch. The harness is the foreman’s notebook — the running record that each incoming worker reads before picking up a tool.
A proper harness separates three distinct memory layers: current task state (what is happening right now, in this session), intermediate results (conclusions reached across prior steps that are still relevant), and long-term memory (user preferences, project patterns, accumulated knowledge across sessions). Mix those together and the system begins compounding its own confusion — intermediate results overwrite task state, stale preferences contaminate fresh decisions. Keep them distinct, with clear rules about what belongs where and how long each persists, and the agent starts behaving like a reliable collaborator rather than a sophisticated amnesiac.
Evaluation, Validation, and Recovery. Here’s a number worth sitting with: if a multi-step agent pipeline succeeds at each individual step 95% of the time, its end-to-end success rate over a 20-step task is only 35.8%. That’s not a bug in a particular system — it’s the mathematics of compounding imperfection. Without frequent evaluation, the agent settles into a posture of permanent self-satisfaction: task executed, box checked, moving on. The errors accumulate quietly, step by step, until the final output is confidently wrong with no trace back to the original deviation.
But evaluation only matters if something can be done with the result. A check that catches a failure and has nowhere to route it is just a slightly more informative crash. Consider what happens without a recovery mechanism: a search returns malformed data at step three; the agent treats it as valid and builds the next four steps on top of it; by step seven, the output is confidently wrong, the original error is invisible, and reconstructing the chain is the only way out. In real production environments, that cascade is the baseline, not the exception.
Anthropic operationalized a solution that’s become influential: Planner, Generator, Evaluator — three agents with strictly separated roles. The Planner converts vague requirements into complete specifications before any execution begins. The Generator implements. The Evaluator runs real QA — not by reading the code in isolation, but by operating the actual product: clicking through pages, testing interactions, verifying real outcomes. Constraints block prohibited actions upfront; validation checks each output before it feeds the next step; recovery routes failures to retry, reroute, or roll back rather than silently propagate. Whoever builds can’t also accept. Without that structural separation, the system works beautifully in demos and fails quietly in production.
Case Study: Claude Code Agent Features
Claude Code is one of the few places you can see harness engineering in production — not a research demo, but a shipping product making concrete engineering decisions every day. Inside it, two distinct multi-agent patterns run on the same foundation. The first is subagent mode: a main agent hits a sub-task that would pollute its focus, spins up a fresh child to handle that piece, and gets a tidy report back. Portable, general-purpose, and you’ll find it across the Anthropic product line. The second is team mode: the main agent becomes a Lead, hires named teammates who stay alive for the whole session, and coordinates through a shared task list. The teammates have their own inboxes, their own working memory, and they talk to each other. Both patterns share the same underlying spine — the same spawn mechanism, the same rules for who gets which tools, the same on-disk records that make recovery possible. The interesting differences are all in what happens after spawn.
Context is the first design decision, and Claude Code makes it unambiguous: by default, nothing crosses. A fresh agent knows none of the conversation it was spawned from. The framework’s own instructions describe the required briefing as treating the new agent like “a smart colleague who just walked into the room — it hasn’t seen this conversation, doesn’t know what you’ve tried, doesn’t understand why this task matters.” If the Lead writes a one-line prompt, the agent runs blind. There is a narrower mode — the fork — where a child inherits the parent’s context exactly. Its purpose is engineering efficiency, not convenience: byte-identical context enables prompt caching, so a second opinion doesn’t double the compute cost. Team mode adds a third kind: team awareness. A teammate knows who the other members are, who the Lead is, and where the team’s working artifacts live — the minimum orientation for coordination. Even this is budgeted: read-only roles like the built-in Explore and Plan agents have the project’s conventions file stripped from their context entirely. The savings: roughly fifteen billion tokens per week. Context isn’t just managed; it’s rationed.
State survives on disk, not in memory. Every agent run streams its full conversation to a JSONL transcript file as it happens. If the process dies, the file is still there; the framework reads it back, strips out half-finished tool calls and noise, and reconstructs the agent’s state — deliberately lossy, aiming for a clean enough record to resume from, not a perfect replay. Team mode adds two more persistence layers: a team file that records who the teammates are (so a crashed session can rebuild the roster), and an inbox file per teammate that holds pending messages (so a message sent to Bob while Bob was offline is still waiting when Bob restarts). Individual agents also maintain durable working notes — decisions made, approaches tried, constraints discovered — that persist across sessions. For human-initiated recovery, /rewind rolls the conversation back to a chosen earlier state. When an agent spirals into a hallucination loop, the fix is structural: return to the state before the wrong turn, not after.
Tools are managed in layers, and the most instructive finding from teams running this setup is that fewer tools produce better results — the Constraint Paradox. Removing tools an agent doesn’t need reduces wrong turns and downstream cascading failures. Claude Code applies this aggressively. A system-wide layer blocks certain tools from any sub-agent: the ones that only make sense at the top-level session, like asking the human a question. A narrower layer restricts background agents to a working subset. Team members get a small bonus tier: task-management tools and inter-teammate messaging. Each role then adds its own allowlist on top. A Lead in coordinator mode has exactly four tools available: spawn an agent, stop a task, send a message, and generate synthetic output. It cannot read a file or run a shell command. Its entire surface area is delegation — by design. MCP tools pass through the access filters unchanged because they’re considered administrator-blessed; the rest of the system does the gating.
Orchestration works differently in each mode. In subagent mode, there is no separate orchestrator — the parent issues subagent calls in a single turn, the framework runs them in parallel, and the parent is the scheduler. In team mode, an explicit orchestrator takes over: the Lead. When a team is created, a team file is written, a task list is initialized, and the Lead is registered with a deterministic identity. From that point, the Lead claims tasks, assigns them based on availability and dependencies, and tracks progress. It cannot implement the tasks; its restricted toolset enforces this. The underlying mechanism is the Mailbox — the literal name in the code, not a metaphor. Every teammate has an inbox file on disk. Sending a message writes to that file; a poller injects it into the recipient’s next turn, tagged with the sender’s identity. Broadcasts fan out to every inbox. Teammates can challenge decisions, ask for clarification, or escalate blockers using structured message types — not text conventions but typed control-flow primitives. One constraint worth naming clearly: only one team is active per session. Parallel exploration still works at finer grain — a subagent can work on its own isolated branch — but the team itself is singular.
Validation is structurally separated from generation. A dedicated verification specialist handles quality control, and its system prompt opens with a line that explains the design in one sentence: “Your job is not to confirm the implementation works — it’s to try to break it.” The verifier is briefed on its own failure modes: verification avoidance, the tendency to read code and write PASS without running anything; being seduced by the first 80%, the tendency to see a polished UI and miss that half the buttons are dead. It cannot modify the project — no file writes, no installs, no git commits. Running alongside it, deterministic guardrails enforce rules no agent can argue with: hooks that fire before or after any tool call, a post-run security audit that flags sensitive actions without blocking progress. The division of labor holds: the verifier catches what the guardrails don’t; the guardrails catch what the verifier might rationalize away.
These aspects of harness engineering— context isolation, on-disk state, tool constraint, explicit orchestration, structural separation of builder and reviewer, transcript-based recovery — applied consistently across both patterns. The subagent pattern is portable delegation, usable anywhere. The team pattern is a full product surface: named teammates, shared task lists, file-backed inboxes, a human operator with a rewind button. What keeps either pattern coherent across a long, complex task isn’t smarter models or better prompts. It’s the enforced discipline of the spine they share.
Engineering, Until it Disappears
There’s one more observation worth making — one that reframes everything above.
Think about what prompt engineering, context engineering, and Harness engineering actually share. Each one exists because AI couldn’t handle something on its own. The model struggled to understand intent, so prompt engineering stepped in. It lacked the right knowledge at runtime, so context engineering emerged. It drifted during long execution chains, so Harness arrived to hold the process together. Every layer is compensatory — a supplement, not an endpoint.
There’s a useful analogy here: nutritional supplements. You take them because your regular diet falls short. But if your meals eventually become nutritious enough, the supplements become redundant. That’s exactly what’s been happening. As models got better at understanding intent, the elaborate prompt-crafting rituals of 2023 matter far less. Context engineering, which once required careful manual work, is now largely absorbed into mature tooling — tools like Claude Code come with memory compression, context management, and conversation state handling built in. Most practitioners don’t think about it anymore. That’s not failure. That’s the discipline succeeding well enough to disappear into the infrastructure.

Harness Engineering is probably on the same trajectory. The patterns teams are hand-building today — evaluation loops, recovery mechanisms, structured state management — will get abstracted into platforms and baked into models. Give it a year or two. The scaffolding becomes load-bearing, then invisible.
The supplement trajectory is real — for end users. Once the engineering is baked into the platform, you simply use the product. The harness becomes invisible. You drive the car home from the dealership without knowing anything about the suspension.
But that presupposes the car is ready at the dealership. Right now, it isn’t. If you’re waiting until it is, you’re not an early adopter — you’re a late one. There are people who need to understand how this works in order to shape it: engineers building pipelines, managers deciding which systems to trust, decision-makers figuring out what to hand to AI and what to keep. For them, the supplement analogy carries a quiet irony. The supplements disappear after someone figures out how to put them in the food. That work is still being done. The scaffolding becomes invisible only after someone makes it load-bearing — and the people doing that need to understand it before it disappears.